
#11: Marketing Mix Modelling — przegląd możliwości na przykładzie Google Meridian
AI, ale bez modeli językowych, czyli o użyciu danych i konkretnych rekomendacjach

Cześć,
jak miałem okazję dać do zrozumienia wielokrotnie na łamach tego newslettera, rynek reklamy jest miejscem skrajnie nietransparentnym. Problemów jest cała masa — od często nieprzejrzystej polityki big techów w zakresie rozwoju produktów (która jest nastawiona na zwiększanie zysków; jako przykład Google i Performance Max), poprzez szereg dostawców technologicznych, gdzie każdy oferujący rozwiązania chce zarobić, agencji i holdingów niekoniecznie ogarniających temat bądź będących w nieuczciwych układach z rekomendowanymi podwykonawcami, kończąc na specyficznych produktach, którym często towarzyszy uczucie “po co mam z tego korzystać?”. Powiedzieć, że jest okrutnie ciężko to jak nic nie powiedzieć, a w dodatku to wszystko obarczone jest ryzykiem bardzo krytycznego procesu, jakim jest przepływ pieniędzy we firmie i odpowiedzialność za przychody; to i tak wierzchołek góry lodowej, gdzie jak dołączysz dane, to robi się jeszcze ciekawiej.
Ostatnie badania Microsoftu i Carnegie Mellon University wyklarowały hipotezę (i tutaj polecam zapoznać się ze samym paperem, gdyż to nie dowodzi tego, że mamy obecnie atrofię intelektu wbrew np. moim osobistym przekonaniom, ale i też wielu sceptyków postępu technologicznego w ogóle), że używanie narzędzi AI doprowadza do zjawiska tzw. mechanicznej konwergencji, czyli sytuacji w ramach której zachodzi standaryzacja sposobu myślenia i ograniczania potrzeby intelektualnego udziału człowieka w pracy. Oto dwa kluczowe wnioski, które chcę wyłuszczyć:
Redukcja wysiłku mentalnego: 62% uczestników przyznało, że używając GenAI do rutynowych zadań (np. generowanie raportów), mniej angażuje się w analizę jakości wyników.
Atrofia umiejętności: Automatyzacja prostych zadań pozbawia pracowników okazji do ćwiczenia osądu, co osłabia zdolność radzenia sobie z niestandardowymi problemami.
Jestem ciekaw oczywiście jak bardzo AI wpłynie na IQ oraz liczę w przyszłości na większą próbę badawczą, jak i badania pogłębione, acz ja nie o tym. Mogę ten tekst kierować teraz w kierunku pytań filozoficznych, typu Czy większość pracy którą robimy jest bezsensowna?, kwestionować obecnego kształtu rynku usług i redefiniować to, że żyliśmy dotychczas w gospodarce informacji, a nie wiedzy, czy pomstować na ludzi na to, że nie są świadomi swoich ograniczeń kognitywnych i nie próbują usprawniać myślenia (klik), przez co skazują siebie na głupotę, acz ja dzisiaj nie o tym.
Boom na generatywną sztuczną inteligencję doprowadził do znacznej, bardzo pozornej dewaluacji talentu (niezależnie jak definiowanego — można się sprzeczać, czy np. pisanie zapytania SQL to jest talent, ale to temat również na inną rozmowę) i sprowadzenia roli człowieka w systemie kapitalistycznym z jednej strony do wszechmogącego (patrz: praktycznie każda aktualizacja LLMa wypuszczona przez czołowych dostawców i ogrom przykładów promptów budujących oprogramowanie) i jednocześnie rubryczki kosztowej w Excelu do zastąpienia (patrz: również praktycznie każda aktualizacja LLMa i liczne głosy ogłaszające masowe bezrobocie za rogiem). Miałem okazję zresztą odnieść się do tego na LinkedIn przy okazji premiery DeepSeek (gdzie to wydarzenie uświadomiło przynajmniej części rynku, że o ile AI zmienia sposób pracy i konsumpcji informacji, tak wszystko rozchodzi się głównie o adopcje i na chwilę obecną żaden z dostawców technologicznych nie ma na tyle istotnej przewagi, by bez przynajmniej efektu sieciowego zwrócić inwestycje w infrastrukturę; nie mówiąc o tym, że wchodzimy w ciekawy paradoks: jaki jest sens robienia czegokolwiek, jeśli AI zrobi to tak, jak chcę? To jest przecież tak tanie, że nawet osoba nietechniczna może zrobić software i po prostu przestać płacić dostawcom, to czemu nie zrobię czegoś swojego?) i wskazać na strukturalne problemy w narracji i naganianiu na całe “AGI” i “Agentów AI” w celu “zwiększenia produktywności”.
W dużym skrócie chodzi mnie o to, że większość, jak nie wszystkie życzenia firm pragnących automatyzować rzeczy na potęgę wymaga wprowadzenia AGI w ścisłym tego słowa rozumieniu, czyli scenariusza ekstremalnego, gdzie technologia będzie autonomiczna i naszym ostatnim zmartwieniem jest to, że nie można znaleźć pracy. Do tego czasu większość automatyzacji, a w szczególności w obszarze danych, w mojej opinii będzie pewnego rodzaju atrofią — raport ładny z tego zrobi się, ale tak po prawdzie, czy takie ujęcie informacji kiedykolwiek było pomocne? A jeśli tak, to czy do tego potrzebujesz AI? Ja osobiście nie spotkałem się z czymś takim, a przez całe życie siedzę w badaniach, liczbach, wykresach, logice i matematyce. O problemie złożoności systemów, ograniczeniach fundamentalnych AI etc. nie wspominam, bo to też inna para kaloszy.
Do czego zmierzam: marketing, który w powszechnym rozumieniu jest mocno spłycony wyłącznie do procesu zakupu powierzchni reklamowej, jest idealnym przykładem styku, gdzie łączy się wiele wymiarów, przez co jest potrzebne myślenie probalistyczne i odejście do logiki jako absolutu. Dopiero wtedy da się zrozumieć narzędzia, którymi się posługuje i tego, do czego one służą oraz na co mogą przełożyć się. Marketing w takim rozumieniu działa jednocześnie w obszarze badań, socjologii, marketingu cyfrowego, operacyjności biznesu etc., gdzie dane ilościowe służą jako reprezentacja mierzalnych aspektów zjawisk, a matematyka dostarcza formalnego języka do ich modelowania i analizy.
Przykładem narzędzia jest Meridian — nowy framework od Google służący do Marketing Mix Modellingu: procesu analitycznego, który wykorzystuje zaawansowane metody statystyczne i ekonometryczne do oceny wpływu poszczególnych działań marketingowych na wyniki biznesowe, takie jak sprzedaż czy rozpoznawalność marki. Dzisiejszy wpis ma na celu pokazanie zastosowania jego w praktyce, tego co można przy pomocy jego zrobić, na co należy uważać, oraz finalnie, do czego to wszystko służy.

Jak możesz zauważyć po trochę długawym wstępie i spisie treści, staram się tworzyć wysoce jakościowe treści — częściowo one mają charakter publicystyczny, częściowo opracowań technicznych. Jeśli nie jesteś na pokładzie mojego newslettera, zachęcam Cię do zapisania się; co prawda, nie będziesz się ze mną zawsze zgadzać, ale poznasz ciekawy punkt widzenia i masz pewność, że nie uznaję kompromisów, jeśli chodzi o jakość :) Piszę rzadko, acz na temat.
O co chodzi w Marketing Mix Modellingu?
W tzw. “branży” atrybucja jest pojęciem odmienianym przez wszystkie przypadki bez właściwego zrozumienia całej mechaniki za tym stojącej. Otóż atrybucja w marketingu cyfrowym to proces określania wartości do poszczególnych kanałów i działań promocyjnych, które prowadzą do konwersji. Innymi słowy, atrybucja marketingowa pozwala na zrozumienie, które elementy kampanii mogły wpłynąć na decyzje klientów i przyczynić się do osiągnięcia założonych celów. Istotne jest tutaj słowo mogły, gdzie pozwolę sobie wprowadzić pojęcia korelacji i przyczynowości.
Korelacja to statystyczna miara opisująca zależność między dwiema lub więcej zmiennymi. W praktyce oznacza to, że zmiany jednej zmiennej często występują równolegle ze zmianami innej zmiennej. Korelacja może być dodatnia (wzrost jednej zmiennej wiąże się ze wzrostem drugiej), ujemna (wzrost jednej zmiennej wiąże się ze spadkiem drugiej) lub zerowa (brak zauważalnego związku). Ważnym aspektem jest to, że korelacja nie implikuje związku przyczynowo-skutkowego – tylko wskazuje na współwystępowanie zmian w danych zmiennych.
Przyczynowość odnosi się do relacji, w której zmiana jednej zmiennej (przyczyny) bezpośrednio powoduje zmianę innej zmiennej (skutku). Ustalenie przyczynowości wymaga wykazania, że istnieje mechanizm, dzięki któremu jedna zmienna wpływa na drugą, co oznacza, że modyfikacja przyczyny prowadzi do przewidywalnych zmian w skutku. Proces identyfikacji przyczynowości często wymaga dodatkowych badań, takich jak eksperymenty czy analizy modelowe, aby wykluczyć wpływ czynników zewnętrznych i potwierdzić bezpośredni związek między zmiennymi.
To wszystko więc zależy bardzo często od obranej definicji i metodyki pracy, bo to, że istnieje korelacja, nie znaczy, że istnieje przyczynowość. Żeby było ciekawiej, przyczynowość w realnych warunkach (mimo, iż z definicji powinna) nie warunkuje korelacji, co wynika najczęściej z różnych zakłóceń lub nieliniowości relacji. Narzucając na to problem z jakością danych marketingowych (gdzie najczęściej mają one charakter deklaratoryjny) robi się problem ciężki w zarządzeniu.
Mając na uwadze powyższe, osobiście uważam, że nie jest możliwe bez znajomości statystyki i ekonometrii w przynajmniej podstawowym wariancie sensowne analizowanie danych, na co zalecam zwracać uwagę przy pracy z agencją marketingową, firmami technologicznymi bądź indywidualnym konsultantami. Ja do tego dołożyłbym jeszcze zagadnienia związane z matematyką dyskretną, acz ww. w zupełności wystarczy, by operować na racjonalnym poziomie.
W marketingu cyfrowym dominujący podział posiada narzędzie Google Analytics i ekosystem Google Marketing Platform. W GA4 wyróżnia się trzy główne modele atrybucji.
Pierwszy, oparty na algorytmie, czyli model data-driven, automatycznie analizuje dane, by precyzyjnie ocenić wkład poszczególnych kanałów w osiągnięcie konwersji, bez stosowania sztywnych reguł: w pierwszym etapie analizowane są dostępne dane ścieżki, obejmujące zarówno użytkowników konwertujących, jak i niekonwertujących, aby opracować modele prawdopodobieństwa wystąpienia kluczowych zdarzeń.
Modele te określają, jak obecność i czas wystąpienia określonych punktów styku z reklamą wpływa na szanse użytkownika na wykonanie kluczowego zdarzenia, porównując prawdopodobieństwo zdarzenia u użytkowników narażonych na ekspozycję reklamową z grupą kontrolną. W drugim etapie algorytmicznie przypisywany jest ułamek kredytu reklamowego – każda interakcja reklamowa otrzymuje wagę na podstawie tego, jak jej dodanie do ścieżki zmienia oszacowane prawdopodobieństwo wystąpienia kluczowego zdarzenia. Algorytm uwzględnia takie cechy, jak odstęp czasowy między interakcją a zdarzeniem, format reklamy oraz inne sygnały, co umożliwia precyzyjne określenie wkładu każdej ekspozycji. Przykładowo, jeśli kombinacja kilku ekspozycji zwiększa prawdopodobieństwo zdarzenia z 2% do 3%, można przypisać określoną ekspozycję z dodatkowym wzrostem o 50% prawdopodobieństwa. Takie podejście umożliwia dynamiczne i precyzyjne rozliczanie wkładu poszczególnych punktów styku na drodze do konwersji.

Powyższy opis bazuje na tym co udostępnia Google w oficjalnej dokumentacji. W praktyce nie jest wiadome co i jak działa, a sam opis powoduje, że odpowiedzi jest kilka - od znanych już wartości Shapleya, przez łańcuchy Markowa (btw. załączam bardzo solidne materiały Witolda Wrodarczyka z Adequate tłumaczące realia tych rozwiązań na przykładach marketingowych — polecam jako uzupełnienie powyższego), kończąc na regresjach logistycznych i gradient boostingu. Co do zasady polecam model data-driven traktować jako czarną skrzynkę (ang. black box) i podchodzić do niego z dużą ostrożnością. Google jest znane ze zmieniania reguł działania narzędzi bez uprzedniego ostrzeżenia, co stało się np. w czerwcu 2024 r., co w połączeniu z brakiem przejrzystości, może stanowić nadużywanie pozycji dominującego podmiotu, gdzie możliwości weryfikacji stanu rzeczy są najczęściej ograniczone i wymagają specjalistycznej wiedzy.
Drugi model — cross-channel rule-based – opiera się na ustalonych regułach, takich jak metoda liniowa, model pozycyjny, metoda oparta na czasie (time decay), a także reguły pierwszego i ostatniego kliknięcia, co pozwala na bardziej zróżnicowaną (lub inaczej ujmowaną) analizę wpływu różnych punktów styku. Trzeci model, ads preferred, również korzysta z reguł, lecz dominuje tu zasada ostatniego kliknięcia, która przypisuje największe znaczenie ostatniemu kontaktowi z reklamą przy podejmowaniu decyzji o konwersji.
Wszystkie modele tutaj wymienione są przyczynowe, nie korelacyjne. Każdy prezentuje inne ujęcie tych samych informacji i ich sposobu procesowania. Oprócz tego należy uwzględnić w prezentowanych danych przez Google Analytics 4 próbkowanie, progowanie i kardynalność. Ich wpływ na ww. modele atrybucji nie jest również do końca przejrzysty w niektórych ujęciach.
Atrybucja zatem pozwala na bardziej punktowe ujęcie sprawy, co nie prezentuje pełnego obrazu (acz jest najczęściej stosowana). Marketing Mix Modeling (MMM) to z kolei zaawansowana metoda analityczna, oparta głównie na korelacyjnych technikach, która pozwala ocenić, jaki wpływ mają różne działania marketingowe (zarówno online, jak i offline) na wyniki biznesowe, takich jak zwrot z inwestycji (ROI). MMM rozdziela sprzedaż na tzw. sprzedaż bazową (wynikającą z czynników niezwiązanych z marketingiem, np. sezonowości, trendów rynkowych czy marki) oraz sprzedaż przyrostową, generowaną dzięki działaniom promocyjnym. Dzięki temu model umożliwia podejmowanie lepszych decyzji dotyczących alokacji budżetu, planowania kampanii i prognozowania efektów działań marketingowych.
Przykładem zastosowania MMM jest platforma Meridian opracowana przez Google.
Meridian to otwartoźródłowy framework do Marketing Mix Modeling, który wykorzystuje podejście bayesowskie do analizy danych marketingowych. Dzięki integracji z ekosystemem Google (np. danymi z Google Ads, YouTube czy Google Analytics), Meridian pozwala precyzyjnie określić, jaki wpływ mają poszczególne kanały marketingowe na sprzedaż. Co więcej, dzięki możliwości wprowadzania priorytetów (priors) i uwzględnianiu efektów opóźnienia (adstock) oraz nasycenia mediów, platforma umożliwia symulację różnych scenariuszy budżetowych oraz optymalizację wydatków.
Zastosowanie z kolei kompletu wyżej wymienionych informacji pozwala na opracowanie spójnej metodyki w celu wykazania przyczynowości oraz faktycznej poprawy rezultatów i wnioskowania z danych.
Jak działa Meridian?
Napiszę teraz jednozdaniową syntezę tego, co można napisać fachowo o Meridianie, a następnie rozłożę ją na czynniki pierwsze:
Meridian działa poprzez wykorzystanie zagregowanych danych marketingowych i KPI, zastosowanie bayesowskiego wnioskowania przyczynowego i modelu regresji z uwzględnieniem efektów opóźnionych i nasycenia mediów, aby oszacować wpływ działań marketingowych, obliczyć metryki takie jak ROI i mROI, wizualizować krzywe odpowiedzi oraz optymalizować alokację budżetu marketingowego, przy jednoczesnym zachowaniu transparentności założeń i możliwości włączenia wiedzy apriorycznej.
Twierdzenie Bayesa to fundamentalna zasada wnioskowania statystycznego, która pozwala na aktualizację naszego przekonania o danym zdarzeniu lub hipotezie na podstawie nowych dowodów. W praktyce oznacza to, że zaczynamy z pewnym początkowym oszacowaniem (tzw. prawdopodobieństwem a priori) i, gdy pojawią się nowe dane, modyfikujemy nasze przekonanie, aby uzyskać bardziej precyzyjne oszacowanie (tzw. prawdopodobieństwo a posteriori). Kluczową ideą jest tu ciągłe uczenie się – im więcej jakościowych dowodów zgromadzimy, tym bardziej dostosowujemy nasze przekonania do rzeczywistości i model będzie stanowił tym wierniejszą reprezentację rzeczywistości.
W kontekście Marketing Mix Modelling (MMM) podejście bayesowskie znajduje zastosowanie w kilku kluczowych obszarach:
Aktualizacja modeli: Bayesowskie metody umożliwiają ciągłą aktualizację modeli MMM w miarę pojawiania się nowych danych marketingowych, co pozwala na lepsze dopasowanie modeli do dynamicznych warunków rynkowych.
Włączenie wiedzy eksperckiej: Dzięki możliwości uwzględnienia wcześniejszej wiedzy (jak np. opóźnienie wpływu reklamy lub nasycenia mediów), modele bayesowskie dostarczają trafnych i wiarygodnych oszacowań wpływu poszczególnych kanałów marketingowych. Dodatkowo budowanie nowych symulacji pozwala na weryfikację krańcowości opłacalności inwestycji w marketing, a co za tym idzie, uważniejsza kontrolę nad kosztami.
Symulacja scenariuszy: Podejście bayesowskie umożliwia generowanie prognoz w postaci pełnych rozkładów prawdopodobieństwa, co pozwala na przeprowadzanie symulacji i testowanie, jak zmiany w budżecie lub strategii mogą wpłynąć na wyniki sprzedażowe.
Uwzględnienie niepewności: Modele te nie tylko dostarczają szacunków wpływu poszczególnych działań, ale również informują o poziomie niepewności tych oszacowań, co jest istotne przy podejmowaniu decyzji dotyczących alokacji budżetu.
Dodatkowo, niezbędne jest stosowanie solidnych metod walidacji, takich jak analiza out-of-sample, cross-validation czy testy A/B. Dzięki nim można bieżąco weryfikować trafność modelu oraz jego zdolność do przewidywania wyników w zmieniającym się otoczeniu rynkowym. Przeprowadzenie analizy wrażliwości, czyli badanie wpływu modyfikacji przyjętych założeń (np. dobór rozkładów apriorycznych) na końcowe wyniki, pozwala na lepsze zrozumienie kluczowych czynników determinujących efektywność kampanii oraz na bardziej precyzyjne zarządzanie niepewnością.
Ważne jest, aby zaznaczyć, że twierdzenie Bayesa samo w sobie nie jest miarą korelacji ani dowodem przyczynowości:
Nie jest korelacją — Korelacja mierzy, jak bardzo zmienne współzmieniają się ze sobą, ale nie informuje o kierunku ani mechanizmie tego związku. Twierdzenie Bayesa służy do aktualizacji prawdopodobieństw na podstawie nowych danych, co może być stosowane zarówno przy analizie korelacji, jak i przyczynowości – w zależności od przyjętych dodatkowych założeń.
Nie jest przyczynowością — Sama metoda bayesowska nie wyjaśnia, czy obserwowany związek jest przyczynowy. Aby uzyskać wnioski o przyczynowości, konieczne jest dodatkowe modelowani oraz przyjęcie specyficznych założeń dotyczących struktury przyczynowej danych.
Najlepiej będzie to potraktować jako narzędzie pozwalające wystandaryzować metodykę pracy i ciągłych eksperymentów, przy jednoczesnym uwzględnieniu nowych danych i kalibracji modelu.
Co jest rezultatem implementacji Meridian? Czy opłaca się to wdrażać?
Rezultatem wdrożenia systemu MMM jest, jak wspomniałem powyżej, kompleksowa informacja na temat funkcjonowania marketingu i jego skuteczności w ramach pewnego zunifikowanego modelu. Meridian sam w sobie jako biblioteka zawiera wbudowane, domyślne raporty, których użyteczność nawet przy podstawowym wdrożeniu jest już mocno pomocna. Oto kilka najciekawszych według przykładów (prosto z dokumentacji Google):
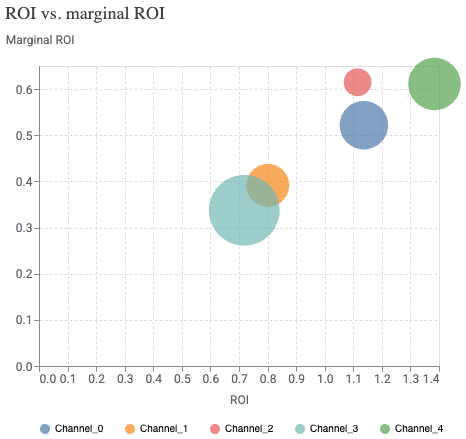
Ocena ROI vs marginal ROI: ROI pokazuje średni zwrot z dotychczasowych inwestycji, podczas gdy mROI wskazuje, jaki będzie zwrot z kolejnej zainwestowanej jednostki budżetu, co pozwala podejmować lepsze decyzje o przyszłych inwestycjach.
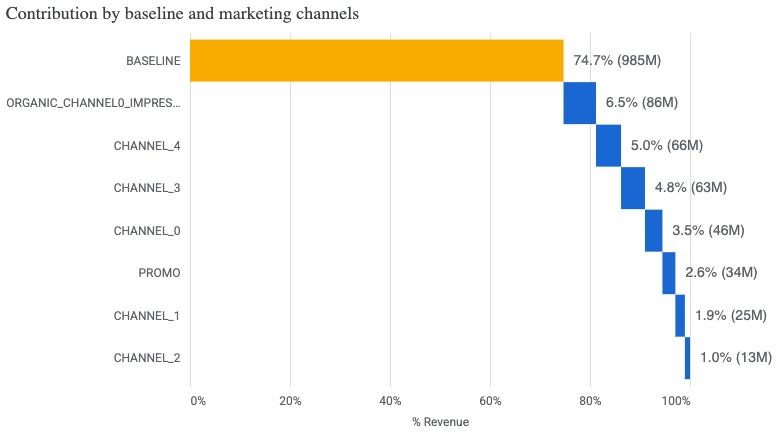
Podział przychodów: Wykres przedstawia dekompozycję przychodów firmy, pokazując jak duża część sprzedaży wynika z naturalnego popytu na produkt (baseline), a jaki wkład w generowanie przychodów mają poszczególne kanały marketingowe, co pozwala ocenić ich względną skuteczność i wpływ na wyniki biznesowe.
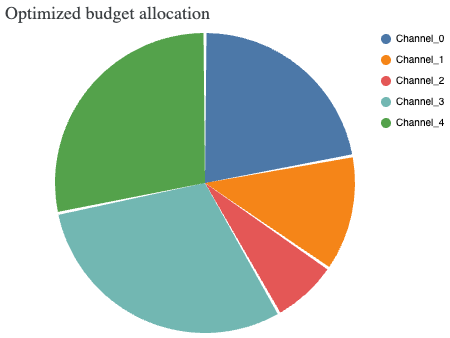
Optymalizacja alokacji budżetu reklamowego na konkretne kanały.
Opłacalność wdrożenia należy ocenić nie pod kątem zasadności tego, czy warto to zrobić, tylko czy dany podmiot/projekt korzysta w ogóle z danych i ma jakkolwiek poukładane sposób zbierania, walidacji, a następnie utylizacji niepotrzebnego szumu. Jeśli nie, to w mojej opinii nie. Jeśli tak, to poza kosztem technologicznym (który zawsze da się zoptymalizować) nie widzę osobiście przeciwwskazań, zwłaszcza że z mojego doświadczenia dostarcza to ciekawszych rekomendacji niż przeciętny analityk marketingowy (chociaż analityk jest tutaj mocnym nadużywaniem tego pojęcia).
W obliczu dynamicznie zmieniającego się krajobrazu technologicznego i rosnącej roli AI, kluczowym wyzwaniem pozostaje nie tylko automatyzacja procesów, ale przede wszystkim zachowanie zdolności krytycznego myślenia. Tylko poprzez ścisłą integrację twardych metod statystycznych z głęboką wiedzą branżową jesteśmy w stanie przekuć suche liczby w realne, trafne rekomendacje decyzyjne. To właśnie dzięki temu, zamiast jedynie mierzyć efektywność kampanii, zyskujemy narzędzie do przewidywania trendów oraz adaptacji do nowych wyzwań, co stanowi fundament nowoczesnego podejścia do marketingu.
Będę wdzięczny za informację zwrotną o tym, czy taka formuła newslettera podoba się. W razie pytań odpisz na tego mejla — chętnie odpowiem i pomogę.
Do przeczytania
Kacper