
#1: Ile prawdziwego ruchu jest w ruchu przychodzącym — jak to zrozumieć?
O przykładzie użycia machine learning niskim kosztem w celu dbania o jakość emisji reklam

Cześć,
na pierwszy wpis w moim newsletterze wrzucę na tapet bardzo kontrowersyjny problem jakim jest jakość ruchu w Internecie z różnych źródeł - od owianego złą sławą SEO, poprzez ruch bezpośredni (często też kwalifikowany jako taki pochodzący z crawlerów, czyli automatycznych robotów), kończąc na kampaniach płatnych, gdzie każdy wydana złotówka ma znaczenie dla końcowego efektu, jakim powinien być rentowny marketing.
Pokażę na przykładach w jaki sposób podejść do analizy danych tego typu, jak poglądowo zbudować system weryfikacji ruchu składający się z gotowych — i co też istotne, bezpłatnych lub niskokosztowych — rozwiązań.

Za podstawę technologiczną do realizacji posłuży w mojej opinii najpopularniejszy stack marketingowy w regionie CEE i kilka dodatkowych rozszerzeń:
Google Analytics 4 — darmowa wersja narzędzia do analityki;
Google BigQuery — chmura obliczeniowa; tutaj sprawa jest zróżnicowana, gdyż finalna kwota zależy od kilku zmiennych, takich jak lokalizacja hostingu, ilość wykonywanych operacji, czy powierzchnia etc. Dla większości zastosowań testowych można spokojnie zakwalifikować się na darmowy plan (Free Tier), który oferuje do 10 GiB powierzchni miesięcznie i procesowanie do 1 TiB danych. Więcej informacji znajdziesz tutaj: klik. Koszt na potrzeby demonstracyjnie nie powinien być znaczący;
Google Tag Manager Server-Side — narzędzie porządkujące kody śledzące we witrynie. Polecana przeze mnie jest forma wdrożenia server-side, o czym pisałem na blogu tutaj i tutaj;
framework Klaro — opensource’owe rozwiązanie do zbudowania własnego Consent Management Platform. Dlaczego nie gotowe CMP to opiszę w dalszej treści artykułu;
Google Cloud Functions — zgodnie z przepisami prawa w momencie obsługi zgód masz obowiązek posiadać rejestr takowych zgód i ich zmian: dzięki Cloud Functions napiszemy sobie prostą aplikację i bazę danych, która będzie suplementem takowego rejestru;
Google reCAPTCHA v3 — przykład podstawy systemu weryfikacji niejakościowego ruchu.
Do tego można byłoby załączyć jeszcze narzędzie służące do analityki użytkowej pokroju HotJar lub Microsoft Clarity, tylko że ze względu na to, iż intencją wpisu jest, by pokazać, jak zrobić taki cały system we względnie prosty sposób, pominę ten krok — z treści mejla będzie potem wynikała ścieżka w jaki sposób można to wdrożyć.
Docelowym, pożądanym rezultatem jest przygotowanie systemu oceny jakości ruchu pochodzącej od konkretnego użytkownika, który wykrywa anomalie na jak najbardziej wczesnym etapie i analizowanie tych informacji.
Na początku jest kluczowe zrozumienie w jaki sposób implementacja powinna przebiegać, a by to słusznie ocenić warto zacząć od końca, czyli w miejscu, gdzie są składowane dane o sesjach: BigQuery.
By zrozumieć strukturę danych w BigQuery zwłaszcza w momencie, gdy użytkownik nie wyraża zgody na zbieranie informacji, trzeba zrozumieć sam zamysł consent mode.
Na końcu z kolei jest prosta droga do tego, jak zaimplementować Consent Management Platform i na jakim etapie można tworzyć cookiesy, podział plików na kategorię oraz jak można interpretować prawo (o tym będzie kilka słów ekstra później).
Google BigQuery
Google Analytics 4 jako rekomendowaną funkcjonalność sugeruje konfigurację analityki wraz ze chmurą obliczeniową BigQuery. Wynika to z kilku powodów:
Google Analytics 4 magazynuje domyślnie dane do 14 miesięcy wstecz, po czym je usuwa. W BigQuery płaci się za powierzchnię przechowywanych danych, dzięki czemu można je przechowywać bezterminowo (a przynajmniej do momentu, dopóki płaci się faktury za świadczenie usługi);
Google Analytics 4 w celu oszczędzania mocy obliczeniowej serwerów służących do bezpłatnego utrzymania aplikacji (gdyż GA4 dalej jest darmowe, zakup licencji GA4 360 jest opcjonalny) poddaje dane procesom próbkowania, progowania i kardynalizacji:
Próbkowanie to technika statystyczna, która polega na wyborze podzbioru z większego zbioru, w celu estymowania cech całej kolekcji. Próbkowanie jest na ogół stosowane, gdy jest zbyt kosztowne lub niemożliwe do badania każdego pojedynczego elementu w całej populacji. Próbki powinny być reprezentatywne dla całości, aby oszacowania były wiarygodne;
Progowanie odnosi się do ustalenia określonego poziomu, powyżej którego lub poniżej którego zaczyna obowiązywać określona reguła lub zachodzi określone zjawisko. Na przykład, w algorytmach uczenia maszynowego, progowanie może by użyte do klasyfikacji wyjść modelu;
Kardynalizacja to pojęcie statystyczne, które odnosi się do liczby unikalnych elementów w zbiorze. W kontekście baz danych, kardynalizacja może odnosić się do liczby unikalnych wartości w kolumnie tabeli. Zarządzanie kardynalizacją jest kluczowe dla efektywnego przetwarzania informacji, szczególnie przy operacjach takich jak sortowanie czy łączenie zbiorów danych;
Istotnym tutaj szczegółem jest to, że dane o tym, jak działa każdy z procesów są udostępnione w okrojonej formie. Zalecam tutaj podejście, że modele od Google są black boxem i zastosować zasadę ograniczonego zaufania.
Z Google BigQuery można wyciągnąć surowe dane pochodzące z GA4 i przeprowadzać na tej bazie danych dowolne operacje bez wpływu na to jak funkcjonują modele obliczeniowe Google w GA4.
Google Consent Mode
Internetowe działania marketingowe od pewnego czasu są nierozerwalnie związane ze zbieraniem informacji o użytkownikach strony internetowej. Te dane są gromadzone najczęściej za pomocą plików cookie, które później wykorzystywane są w ramach kampanii cyfrowych. Im więcej danych mamy o użytkowniku, tym precyzyjniejszą personalizację naszej oferty, przekazu marketingowego lub kanału komunikacji możemy zastosować.
Jednakże, od 25 maja 2018 roku, przepisy RODO (GDPR) zabraniają używania plików cookie bez zgody użytkownika. Dlatego, aby nadal móc korzystać z możliwości, jakie dają ciasteczka, strony internetowe muszą uzyskać na to zgodę. W tym procesie kluczową rolę odgrywa Consent Mode.
Consent Mode jest to standard, który polega na umieszczaniu na stronie internetowej specjalnego banneru informującego użytkowników o wykorzystywaniu plików cookie. Użytkownicy mają możliwość wyrażenia zgody na korzystanie z ciasteczek lub jej odrzucenia.
Consent Mode zakłada, że skrypty od stron trzecich, generujące pliki cookie na stronie użytkownika, mogą być uruchamiane tylko po uzyskaniu zgody. Może to obejmować różnorodne kwestie, takie jak zbieranie danych analitycznych, ustawianie plików cookie, personalizowanie treści, śledzenie działań użytkowników dla celów marketingowych.
Jeśli użytkownik kompletnie odrzuci zgody, korzystanie z plików cookie powinno zostać ograniczone do minimum niezbędnego dla działania strony, co de facto oznacza zablokowanie tagów od stron trzecich. Gdy zgoda zostanie udzielona tylko częściowo, działanie tagów powinno być modyfikowane tak, aby respektowało udzielone zgody, co oznacza aktywację tylko tych tagów, które pasują do zaakceptowanych kategorii.
Google Consent Mode umożliwia gromadzenie zgód użytkowników podzielonych na konkretne kategorie:
analytics_storage - zgoda na wykorzystanie plików cookie do celów statystycznych;
ad_storage – zgoda na korzystanie z plików cookie dla potrzeb reklamowych;
ad_user_data – zgoda na przekazywanie do Google danych użytkownika do wykorzystania w reklamach online;
ad_personalization – zgoda na personalizację reklam;
functionality_storage – zgoda na wykorzystanie plików cookie, które wspierają funkcjonalności strony;
security_storage – zgoda na przechowywanie danych z funkcji bezpieczeństwa;
personalization_storage – zgoda na wykorzystanie plików cookie do personalizacji treści na stronie.
Każda z tych zgód może przyjąć jeden z dwóch stanów:
denied – zgoda nie została udzielona;
granted – zgoda została udzielona.
W sytuacji, gdy zgody nie są udzielone, tagi Google nie zapisują plików cookie na stronie użytkownika, ale przekazują minimalne informacje o aktywności użytkownika, zwanymi sygnałami. Sygnały dostarczają kluczowych danych ilościowych, na podstawie których potem Google realizuje modelowanie behawioralne (acz dopiero po spełnieniu określonych warunków).

I teraz ważne: jak to wpływa na dane w Google BigQuery?
Główną różnicą w eksporcie BigQuery dla danych pochodzących z sesji, w których zgoda analytics_storage została odrzucona, jest brak danych do modelowania behawioralnego. W rezultacie nie można standardowo wiązać użytkowników i sesji ze względu na brak dwóch kluczowych wymiarów: user_pseudo_id i ga_session_id.
Należy jednak pamiętać, że user_id jest dostępnym wymiarem w danych pochodzących z sesji z odrzuconą zgodą analytics_storage - nie mówiąc o innych wymiarach niestandardowych, które można względnie swobodnie definiować :)
Consent Management Platform
Po tym dość szczegółowym wyjaśnieniu można przejść do roli CMP. Consent Management Platform, jak sama nazwa wskazuje, to mechanizm obsługi tych zgód. Dla użytkowników najczęściej objawiają się one w postaci takich powiadomień przy wejściu na stronę internetową:
Poza samym wyrażeniem zgody, jako potencjalny dostawca usług masz obowiązek przechowywać informacje o tym, kto w ramach jakiej sesji wyraził zgodę bądź nie oraz respektować możliwość zmiany takowej zgody w każdym momencie. Trochę tych obowiązków jest, a wraz z nimi dochodzi mnogość scenariuszy w których użytkownik w ujęciu analityki może zmienić swój stan: teraz jak w tym połapać się?
Do napisania tego mejla zainspirował mnie wpis Adama Brzostka z firmy Better Steps, który na blogu porusza (co prawda zdawkowo, ale jednak - ogólnie z takim podejściem do pracy z zdanymi rzadko spotykam się w branży, co bywa obiektem mojego niezrozumienia i frustracji) mniej więcej to, co ja napisałem powyżej: na rozwiązanie problemu zliczania użytkowników i sesji proponuje stworzenie niezależnego klucza pośredniego, który byłby referencją do wiązania między sobą sesji - niezależnie od tego, czy użytkownik na to wyrazi zgodę, czy nie.
Pomysł jest bardzo w porządku, jednak adresuje tylko podstawowo problem: w jaki sposób wiązać sesje między anonimowymi zdarzeniami i je potem oceniać? Otóż klucz pośredni jest utworzony przy pomocy sessionStorage na bazie timestampa, co może i spełnia rozwiązanie problemu postawionego w artykule, tak jest dość wąskie i nieprecyzyjnie. Właściwie to powinno wyglądać tak:
ustawiam w sessionStorage wartość przy wejściu jeśli jej nie wykryto. Tutaj zdecydowanie sprawdzi się UUID, które można byłoby jeszcze opcjonalnie przepuścić BCryptem, tak by ograniczyć w bardzo długiej perspektywie ryzyko powtarzalności danego klucza;
w momencie jeśli użytkownik nie ma wyrażonej zgody i dalej nie wyrazi zgodę na analytics_storage pozostawić bez zmian i przesyłać klucz przy zdarzeniach;
w momencie jeśli użytkownik nie ma wyrażonej zgody i dalej wyrazi zgodę na analytics_storage pozostawić bez zmian i przesyłać klucz przy zdarzeniach;
gdy użytkownik zmieni zgodę analytics_storage to niezależnie od tego jaki będzie końcowy stan należy taki klucz usunąć i stworzyć nowy, dodatkowo polecałbym przeładowania karty przeglądarki i/lub kodów śledzących.
Wynika to z tego, że sessionStorage przeglądarki definiują jako okres aktywności użytkownika na stronie internetowej lub w aplikacji od momentu otwarcia do zamknięcia przeglądarki lub wygaśnięcia sesji po określonym czasie nieaktywności. Jaka to konkretnie definicja? Nie znalazłem takich informacji, a prawdę mówiąc lubię rozumieć co się dzieje, więc dla bezpieczeństwa zakładam, że może być wydłużany w nieskończoność. Dzięki tej poprawce nie ryzykuję, że mogę powiązać sesje użytkownika niezależnie od stanu jego zgód, czyli w istocie łamać przepisy.
Oprócz tego poruszę temat tego, jak można rozumieć niezbędne pliki cookies. Aby zdefiniować niezbędne pliki cookie, należy zapewnić i udowodnić, że są one niezbędne do działania strony internetowej lub aplikacji.
Pliki cookie uważane za niezbędne są zazwyczaj używane do:
• Zapamiętania produktów dodanych do koszyka w sklepie internetowym;
• Umożliwienia logowania użytkowników;
• Zabezpieczenia strony przed atakami;
• Personalizacji ustawień użytkownika.
Do realizacji zadań z punktu 3. dzięki m.in. właściwościom struktury danych z Google BigQuery i Google Consent Mode można użyć… Google reCAPTCHA, dzięki czemu można określić zasadność tworzenia ciasteczek w przeglądarkach mimo wyrażenia braku zgody. Nie traktuj tego jako porady prawnej, a przed wdrożeniem tego produkcyjnie skonsultuj to z adwokatem lub radcą prawnym.
Google reCAPTCHA
reCAPTCHA jest usługą firmy Google, która ma na celu ochronę stron internetowych przed spamem, zautomatyzowanymi atakami oraz nadużyciami internetowymi. Jest to narzędzie, które pozwala zweryfikować, czy interakcje na stronie są dokonywane przez ludzi, a nie przez boty komputerowe.
Wersje reCAPTCHA to:
reCAPTCHA v2: W tej wersji użytkownik jest proszony o rozwiązanie testu CAPTCHA, aby dowieść, że jest człowiekiem. Może to być weryfikacja poprzez zaznaczenie odpowiednich pól lub rozwiązanie prostego zadania, takiego jak rozpoznawanie obrazów. reCAPTCHA v2 jest bardziej interaktywna i wymaga zaangażowania użytkownika w proces weryfikacji;
reCAPTCHA v3: Jest to bardziej ukryta forma reCAPTCHA, która działa w tle i nie wymaga interakcji użytkownika. Działa na zasadzie oceny ryzyka każdej interakcji z witryną, nadając im określony stopień ryzyka. Na podstawie tych ocen, administratorzy mogą podejmować decyzje dotyczące zabezpieczeń witryny. reCAPTCHA v3 jest subtelniejsza dla użytkowników, ponieważ nie wymaga od nich interakcji w celu udowodnienia, że są ludźmi.
Dlaczego by więc jej nie użyć jako systemu punktowego interakcji użytkownika?
Sam sposób jej implementacji jest dość prosty, na przykład podążając za oficjalną dokumentacją techniczną:
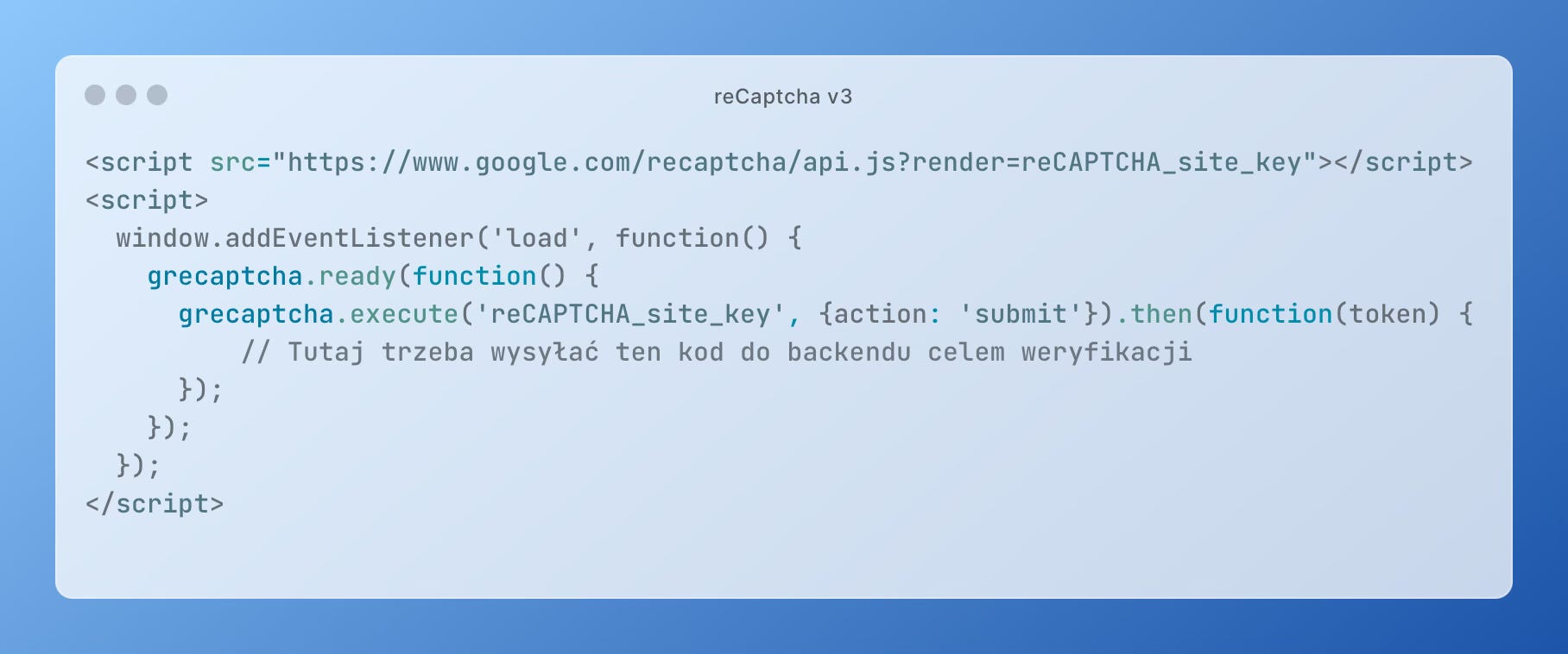
Następnie, wystarczy wysłać kod zwrotny (token) do załadowanego uprzednio Google Tag Manager Server-Side, odpytać serwery Google, a po poprawnej weryfikacji wrócić z wynikiem — w ten sposób można prostym sposobem ocenić sesję użytkownika i robić to każdorazowo, gdy unikalny klucz pośredni jest tworzony (co ograniczy chociażby wykorzystywanie zasobów GTM Server-Side).
Jak załadować CMP, czyli dlaczego zrobiłbym to samodzielnie? Google Cloud Functions w praktyce
Bardzo mocno są spopularyzowane startupy legaltechowe, które dzięki wymogom Komisji Europejskiej mają możliwość dostarczania rozwiązań ułatwiających wdrożenie CMPków — jednym z nich jest polecany przeze mnie CookieYes.
Na potrzeby tego wdrożenia wolę pokazać to w jaki sposób zróbić to dzięki open source’owemu frameworkowi Klaro, gdzie rzecz sprowadza się jak widzisz głównie do umiejętnego zarządzania konfiguracją. Porównanie tego z kolei czy lepszy jest darmowy CMP czy płatny oraz przykład implementacji Klaro znajdziesz tutaj: klik.
Następnie, w zręczny sposób jesteś w stanie do Google Tag Manager Server-Side przesyłać informacje o statusie konkretnej zgody, a potem przechowywać to w Google Cloud Functions — na przykład tak:
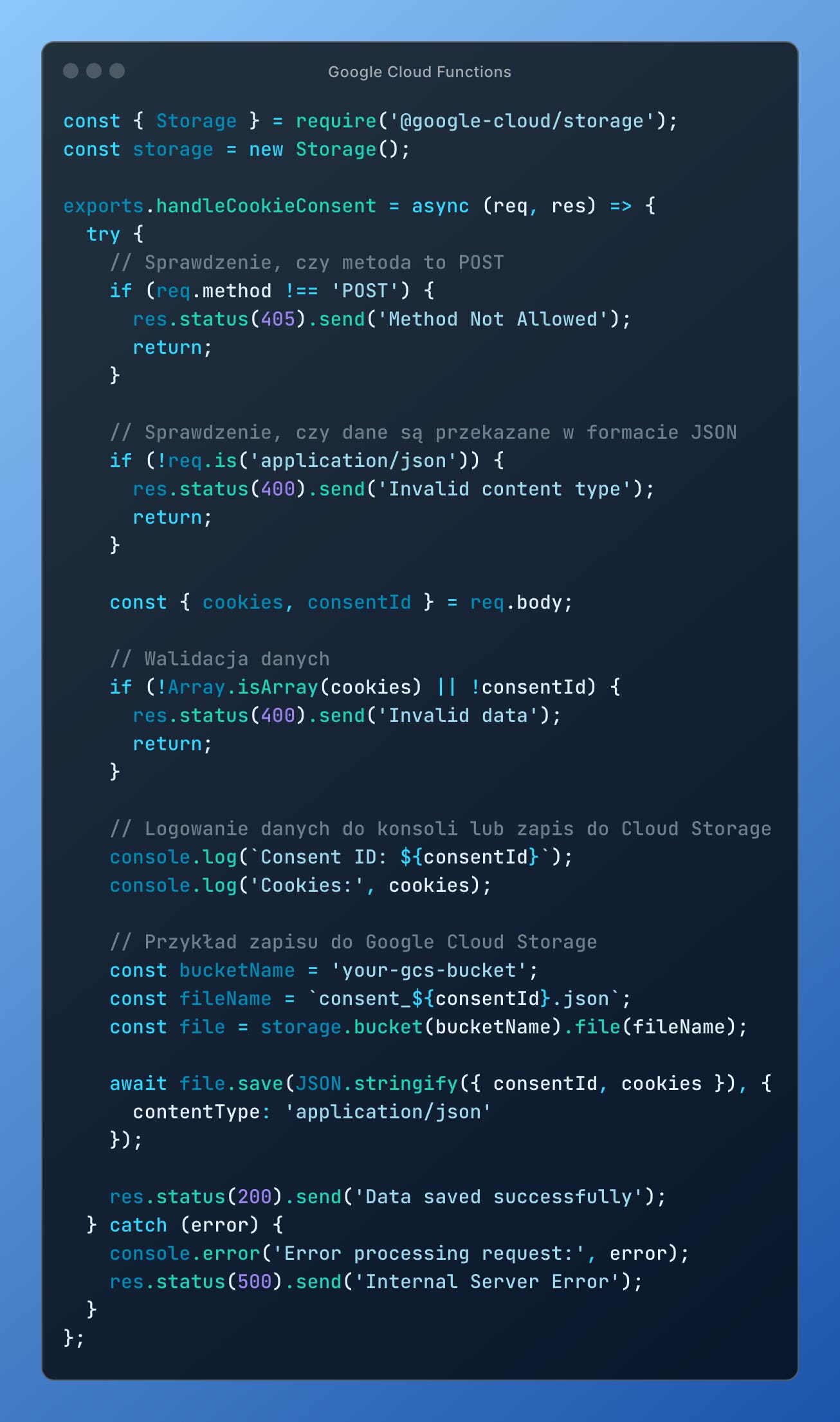
To wszystko
Będę wdzięczny za informację zwrotną o tym, czy taka formuła newslettera podoba się. W razie pytań odpisz na tego mejla — chętnie odpowiem i pomogę.
Do przeczytania
Kacper